Google ColaboratoryでMeCabを利用できるようにするには、Colaboratory上でNotebookを作成し、コードセルに以下の入力を行って実行する(サンプル)。
!apt install aptitude !aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y !pip install mecab-python3==0.996.5
次にMeCabをインポートする。
import MeCab
分かち書きをする場合は引数に"-Owakati"を設定する。
tagger = MeCab.Tagger("-Owakati")
text = "今日はいい天気ですね。"
print(tagger.parse(text))
【実行結果】
今日 は いい 天気 です ね 。
形態素属性を出力する場合は引数に何も設定しない。
tagger = MeCab.Tagger() text = "今日はいい天気ですね。" print(tagger.parse(text))
【実行結果】
今日 名詞,副詞可能,*,*,*,*,今日,キョウ,キョー は 助詞,係助詞,*,*,*,*,は,ハ,ワ いい 形容詞,自立,*,*,形容詞・イイ,基本形,いい,イイ,イイ 天気 名詞,一般,*,*,*,*,天気,テンキ,テンキ です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス ね 助詞,終助詞,*,*,*,*,ね,ネ,ネ 。 記号,句点,*,*,*,*,。,。,。 EOS
茶筌フォーマットで形態素属性を出力する場合は引数に"-Ochasen"を設定する。
tagger = MeCab.Tagger("-Ochasen")
text = "今日はいい天気ですね。"
print(tagger.parse(text))
【実行結果】
今日 キョウ 今日 名詞-副詞可能 は ハ は 助詞-係助詞 いい イイ いい 形容詞-自立 形容詞・イイ 基本形 天気 テンキ 天気 名詞-一般 です デス です 助動詞 特殊・デス 基本形 ね ネ ね 助詞-終助詞 。 。 。 記号-句点 EOS
parseToNode
tagger = MeCab.Tagger()
sample = "今日はいい天気ですね。"
node = tagger.parseToNode(sample)
while node:
print(f'surface={node.surface}, feature={node.feature}')
node = node.next
【実行結果】
surface=, feature=BOS/EOS,*,*,*,*,*,*,*,* surface=今日, feature=名詞,副詞可能,*,*,*,*,今日,キョウ,キョー surface=は, feature=助詞,係助詞,*,*,*,*,は,ハ,ワ surface=いい, feature=形容詞,自立,*,*,形容詞・イイ,基本形,いい,イイ,イイ surface=天気, feature=名詞,一般,*,*,*,*,天気,テンキ,テンキ surface=です, feature=助動詞,*,*,*,特殊・デス,基本形,です,デス,デス surface=ね, feature=助詞,終助詞,*,*,*,*,ね,ネ,ネ surface=。, feature=記号,句点,*,*,*,*,。,。,。 surface=, feature=BOS/EOS,*,*,*,*,*,*,*,*
parseToNodeメソッドは形態素を表層(surface)と属性(feature)から構成されるノードとして取り出す。次のノードはnext属性で与えられる。
feature属性は次のフォーマットをしている。
品詞,品詞細分類1,品詞細分類2,品詞細分類3,活用形,活用型,原形,読み,発音
よって、品詞を取り出すには次のようにする。
tagger = MeCab.Tagger()
sample = "今日はいい天気ですね。"
node = tagger.parseToNode(sample)
while node:
POS = node.feature.split(',')[0]
print(f'surface={node.surface}, POS={POS}')
node = node.next
【実行結果】
surface=, POS=BOS/EOS surface=今日, POS=名詞 surface=は, POS=助詞 surface=いい, POS=形容詞 surface=天気, POS=名詞 surface=です, POS=助動詞 surface=ね, POS=助詞 surface=。, POS=記号 surface=, POS=BOS/EOS
これを使うと、名詞を取り出して分かち書きするプログラムは次のようになる。
tagger = MeCab.Tagger()
sample = "今日はいい天気ですね。"
node = tagger.parseToNode(sample)
words = []
while node:
POS = node.feature.split(',')[0]
if POS == '名詞':
words.append(node.surface)
node = node.next
print(f'words={words}')
print(' '.join(words))
【実行結果】
words=['今日', '天気'] 今日 天気
指定した品詞だけを抽出して分かち書きする関数
指定した品詞だけを抽出して分かち書きする関数wakati_gakiを下記に示す。
def wakati_gaki(text):
tagger = MeCab.Tagger()
node = tagger.parseToNode(text)
words = []
while node:
POS = node.feature.split(',')[0]
if POS in ['名詞', '動詞', '形容詞', '副詞']:
words.append(node.surface)
node = node.next
return ' '.join(words)
sample = "今日はいい天気ですね。"
print(wakati_gaki(sample))
【実行結果】
今日 いい 天気
Bag of Wordsによるテキスト表現
コーパスを分かち書きする。
texts = ["今日はいい朝ですね。", "明日もいい朝だといいですね。"]
tagger = MeCab.Tagger("-Owakati")
wakati_texts = [tagger.parse(text).rstrip() for text in texts]
print(wakati_texts)
【実行結果】
['今日 は いい 朝 です ね 。', '明日 も いい 朝 だ と いい です ね 。']
3行目でtagger.parse(text)にrstrip()メソッドをつけているのは、tagger.parse(text)は末尾に改行(\n)を付加するので、それを除去するためである。
CountVectorizerによるBoW表現
分かち書きされたコーパスをsklearnのCountVectorizerを使ってBoW表現する。
from sklearn.feature_extraction.text import CountVectorizer
vect = CountVectorizer(token_pattern='(?u)\\b\\w+\\b')
vect.fit(wakati_texts)
print(f"Vocabulary size:{len(vect.vocabulary_)}")
print(f"Vocabulary content:\n{vect.vocabulary_}")
【実行結果】
Vocabulary size:10
Vocabulary content:
{'今日': 7, 'は': 5, 'いい': 0, '朝': 9, 'です': 2, 'ね': 4, '明日': 8, 'も': 6, 'だ': 1, 'と': 3}
sklearnのCountVectorizerは英語の文章を読み込んでトークン分割し、ボキャブラリを構築するクラスである。英語は単語を空白文字で区切っているのでトークン分割は容易だが、日本語はそうなっていないので、MeCabで分かち書きしてからCountVectorizerへ渡す必要がある。
また、CountVectorizerは1文字の単語(例えば定冠詞の「a」など)を無視するので、コンストラクタの引数にtoken_pattern='(?u)\\b\\w+\\b'を指定して、たとえ1文字でもトークンであると認識して無視しないようにしなければならない。
CountVectorizerのインスタンスvectはfitメソッドで分かち書きされた日本語文章wakati_textを読み込んでボキャブラリを構築する(vect.vocabulary_)。これはディクショナリ型のデータで、ボキャブラリ(語彙)をキーとして、語彙インデックスがバリューとなっている辞書データである。
次に、transformメソッドで分かち書きされた日本語文章をBoW表現にする。
bag_of_words = vect.transform(wakati_texts) print(bag_of_words)
【実行結果】
(0, 0) 1 (0, 2) 1 (0, 4) 1 (0, 5) 1 (0, 7) 1 (0, 9) 1 (1, 0) 2 (1, 1) 1 (1, 2) 1 (1, 3) 1 (1, 4) 1 (1, 6) 1 (1, 8) 1 (1, 9) 1
出来上がったBoW表現はSciPyの疎行列として格納されている。実行結果の1列目のタプルは先頭要素が行インデックス、2番目の要素が語彙インデックスを表し、2列目の数字が文中に出現する頻度を表している。例えば実行結果の1行目は最初の文には「いい」が1つあり、7行目は2番目の分には「いい」が2つあることを示している。
この疎行列を普通の「密な」NumPy行列に変換するにはtoarray()メソッドを使う。
print(bag_of_words.toarray())
【実行結果】
[[1 0 1 0 1 1 0 1 0 1] [2 1 1 1 1 0 1 0 1 1]]
実行結果は、1つ目の文は語彙インデックス0, 2, 4, 5, 7, 9の語彙を一つずつ含むことを示している。
テキスト分類
Excelで行ったテキスト分類をPythonでやってみる。コーパスは3つの抄録とし、以下に示す。
texts = [ '症例は78歳女性。72歳時に近医にてParkinson病、高血圧症の診断となり加療が開始された。74歳時に治療抵抗性高血圧症として紹介となり、降圧薬を複数内服するも十分な降圧が得られないまま経過していた。78歳時、一過性脳虚血発作を契機に、全身の動脈硬化の再評価を行った。Ankle brachial pressure index(以下ABI)右0.59、左0.57と両側で低下を認め、背部・心窩部の聴診にて著明な収縮期雑音を聴取した。造影CTでは下肢動脈の開存は保たれていたが、胸腹部大動脈移行部に狭窄を認め、下肢血流低下および血管雑音の原因と考えられた。また、両側内胸動脈から両側大腿動脈への側副血行路も確認された。大動脈造影では同部位に実測74.7%の狭窄を認め、Mid-aortic syndromeの診断となった。同時圧測定では近位側218/52mmHg、遠位側146/51mmHgと、収縮期血圧で72mmHgの圧較差を認めた。冠動脈造影では3枝ともに有意狭窄を認めた。脈管性高血圧は狭窄部自体への介入、および合併する動脈硬化性疾患(狭心症、心筋梗塞、脳梗塞、脳出血)、心不全等の管理が予後改善に繋がるため、その診断が重要である。本症例は高齢であることから、大動脈狭窄自体に対する侵襲的加療は行わず、合併した虚血性心疾患に対し血行再建を行い、内服で可能な限りの降圧療法を継続する方針とした。(著者抄録)', '甲状腺腫瘍が総頸動脈解離の原因となった既報はなく,脳卒中科のみならず耳鼻科領域においても臨床上重要と思われるため報告する.症例は76歳女性,72歳時に左甲状腺腫瘍を指摘されたが,吸引細胞診で悪性所見なく経過観察となった.76歳時,突然の意識障害と右片麻痺で搬送され,NIHSSスコアは22点だった.MRIで左総頸~内頸動脈に解離を認めたが急性期脳梗塞巣はなく,検査中に症状は寛解した.ヘパリンナトリウムで治療開始し翌日には無症状となったが,頭部前屈に伴い意識消失と右片麻痺が出現するTIAを2回生じた.入院第5病日よりTIAは消失し,MRIで動脈解離の改善を確認し,第29病日に退院した.後日腫瘍は摘出され,頸動脈への浸潤は認めなかったが,病理検査で濾胞癌と診断された.本例では左総頸動脈が長径約5cmの甲状腺腫瘍に圧排され,血管の過伸展や屈曲,血管分岐部の牽引力により外傷性動脈解離を発症したと考えられた.(著者抄録)', '51歳男性。突然の頭痛、嘔吐、めまいを主訴に救急搬送された。高血圧症、脂質異常症、糖尿病、左同名半盲で発症した脳梗塞、左椎骨動脈の高度狭窄による一過性脳虚血発作の既往がある。頭部CT所見で第四脳室の脳室内出血、cerebellomedullary fissureにくも膜下出血を認めHunt & Kosnik分類grade IIと診断した。また、脳血管造影より出血源は左後下小脳動脈(PICA)末梢に存在し、左右のPICA vermian branchをつなぐ側副血管に生じた紡錘状破裂動脈瘤と診断した。両側後頭下開頭でtrappingし動脈瘤摘出を行った。術後、神経症状は認めない。' ]
このコーパスを形態素解析し、名詞のみ抽出した分かち書きにするプログラムを以下に示す。
def wakati_gaki(text):
tagger = MeCab.Tagger()
node = tagger.parseToNode(text)
words = []
while node:
POS = node.feature.split(',')[0]
if POS in ['名詞']:
words.append(node.surface)
node = node.next
return ' '.join(words)
wakati_texts = [wakati_gaki(text) for text in texts]
for i in range(3):
print(wakati_texts[i])
実行結果を以下に示す。
症例 78 歳 女性 72 歳 時 医 Parkinson 病 高血圧 症 診断 加療 開始 74 歳 時 治療 抵抗 性 高 血圧 症 紹介 降圧 薬 複数 内服 十分 降圧 まま 経過 78 歳 時 一過性脳虚血発作 契機 全身 動脈 硬化 評価 Ankle brachial pressure index ( 以下 ABI ) 右 0 . 59 左 0 . 57 両側 低下 背部 心 窩部 聴診 明 収縮 期 雑音 聴取 造影 CT 下肢 動脈 開 存 胸 腹部 大動脈 移行 部 狭窄 下肢 血 流 低下 血管 雑音 原因 両側 内 胸 動脈 両側 大腿 動脈 側 血行 路 確認 大動脈 造影 部位 実測 74 . 7 % 狭窄 Mid - aortic syndrome 診断 同時 圧 測定 位 側 218 / 52 mmHg 位 側 146 / 51 mmHg 収縮 期 血圧 72 mmHg 圧較 差 冠動脈 造影 3 枝 とも 有意 狭窄 脈 管 性 高 血圧 狭窄 部 自体 介入 合併 動脈 硬化 性 疾患 ( 狭心症 心筋梗塞 脳 梗塞 脳出血 )、 心不全 等 管理 予後 改善 ため 診断 重要 症例 高齢 こと 大動脈 狭窄 自体 侵襲 的 加療 合併 虚 血 性 心 疾患 血行 再建 内服 可能 限り 降圧 療法 継続 方針 ( 著者 抄録 ) 甲状腺 腫瘍 頸動 脈 解離 原因 既報 , 脳卒中 科 耳鼻 科 領域 臨床 上 重要 ため 報告 . 症例 76 歳 女性 , 72 歳 時 左 甲状腺 腫瘍 指摘 , 吸引 細胞 悪性 所見 経過 観察 . 76 歳 時 , 意識 障害 右 片 麻痺 搬送 , NIHSS スコア 22 点 . MRI 左 頸 ~ 内 頸動 脈 解離 急性 期 脳 梗塞 巣 , 検査 中 症状 寛解 . ヘパリンナトリウム 治療 開始 翌日 症状 , 頭部 屈 意識 消失 右 片 麻痺 出現 TIA 2 回 . 入院 5 病 日 TIA 消失 , MRI 動脈 解離 改善 確認 , 29 病 日 退院 . 後日 腫瘍 摘出 , 頸動 脈 浸潤 , 病理 検査 濾胞 癌 診断 . 例 左 頸動 脈 長径 5 cm 甲状腺 腫瘍 圧排 , 血管 伸展 屈曲 , 血管 分岐 部 牽引 力 外傷 性 動脈 解離 発症 .( 著者 抄録 ) 51 歳 男性 頭痛 嘔吐 めまい 訴 救急 搬送 高血圧 症 脂質 異常 症 糖尿 病 左 同名 盲 発症 脳 梗塞 左 椎骨 動脈 高度 狭窄 一過性脳虚血発作 既往 頭部 CT 所見 四 脳 室 脳 室内 出血 cerebellomedullary fissure くも膜 下 出血 Hunt & Kosnik 分類 grade II 診断 脳 血管 造影 出血 源 左 後 小脳 動脈 ( PICA ) 末梢 存在 左右 PICA vermian branch 側 血管 紡錘 状 破裂 動脈 瘤 診断 両側 後 頭 下 開 頭 trapping 動脈 瘤 摘出 術後 神経症 状
この分かち書きからCountVectorizerを使ってボキャブラリを作成するプログラムを以下に示す。
from sklearn.feature_extraction.text import CountVectorizer
vect = CountVectorizer(token_pattern='(?u)\\b\\w+\\b')
vect.fit(wakati_texts)
print(f"Vocabulary size:{len(vect.vocabulary_)}")
print(f"Vocabulary content:\n{vect.vocabulary_}")
この結果は以下のとおりである。
Vocabulary size:241
Vocabulary content:
{'症例': 164, '78': 16, '歳': 143, '女性': 99, '72': 13, '時': 135, '医': 78, 'parkinson': 35, '病': 161, '高血圧': 238, '症': 163, '診断': 215, '加療': 76, '開始': 225, '74': 14, '治療': 144, '抵抗': 124, '性': 119, '高': 236, '血圧': 207, '紹介': 185, '降圧': 226, '薬': 204, '複数': 211, '内服': 68, '十分': 79, 'まま': 46, '経過': 186, '一過性脳虚血発作': 50, '契機': 98, '全身': 66, '動脈': 77, '硬化': 173, '評価': 216, 'ankle': 18, 'brachial': 20, 'pressure': 37, 'index': 29, '以下': 58, 'abi': 17, '右': 83, '0': 0, '59': 11, '左': 110, '57': 10, '両側': 54, '低下': 61, '背部': 192, '心': 115, '窩部': 178, '聴診': 191, '明': 134, '収縮': 81, '期': 137, '雑音': 229, '聴取': 190, '造影': 219, 'ct': 24, '下肢': 53, '開': 224, '存': 100, '胸': 193, '腹部': 200, '大動脈': 96, '移行': 177, '部': 220, '狭窄': 156, '血': 206, '流': 145, '血管': 208, '原因': 80, '内': 67, '大腿': 97, '側': 64, '血行': 209, '路': 217, '確認': 174, '部位': 221, '実測': 102, '7': 12, 'mid': 31, 'aortic': 19, 'syndrome': 38, '同時': 86, '圧': 91, '測定': 148, '位': 60, '218': 3, '52': 9, 'mmhg': 32, '146': 1, '51': 8, '圧較': 93, '差': 112, '冠動脈': 70, '3': 6, '枝': 139, 'とも': 45, '有意': 136, '脈': 195, '管': 180, '自体': 202, '介入': 57, '合併': 84, '疾患': 160, '狭心症': 155, '心筋梗塞': 117, '脳': 196, '梗塞': 140, '脳出血': 197, '心不全': 116, '等': 179, '管理': 181, '予後': 56, '改善': 128, 'ため': 44, '重要': 222, '高齢': 239, 'こと': 43, '侵襲': 63, '的': 170, '虚': 205, '再建': 69, '可能': 82, '限り': 227, '療法': 167, '継続': 187, '方針': 130, '著者': 203, '抄録': 123, '甲状腺': 157, '腫瘍': 199, '頸動': 235, '解離': 213, '既報': 131, '脳卒中': 198, '科': 176, '耳鼻': 189, '領域': 230, '臨床': 201, '上': 51, '報告': 94, '76': 15, '指摘': 125, '吸引': 87, '細胞': 184, '悪性': 120, '所見': 122, '観察': 212, '意識': 121, '障害': 228, '片': 152, '麻痺': 240, '搬送': 126, 'nihss': 34, 'スコア': 48, '22': 4, '点': 151, 'mri': 33, '頸': 234, '急性': 118, '巣': 109, '検査': 142, '中': 55, '症状': 165, '寛解': 105, 'ヘパリンナトリウム': 49, '翌日': 188, '頭部': 233, '屈': 107, '消失': 147, '出現': 71, 'tia': 39, '2': 2, '回': 90, '入院': 65, '5': 7, '日': 133, '29': 5, '退院': 218, '後日': 114, '摘出': 127, '浸潤': 146, '病理': 162, '濾胞': 150, '癌': 168, '例': 62, '長径': 223, 'cm': 23, '圧排': 92, '伸展': 59, '屈曲': 108, '分岐': 73, '牽引': 153, '力': 75, '外傷': 95, '発症': 169, '男性': 158, '頭痛': 232, '嘔吐': 88, 'めまい': 47, '訴': 214, '救急': 129, '脂質': 194, '異常': 159, '糖尿': 182, '同名': 85, '盲': 171, '椎骨': 141, '高度': 237, '既往': 132, '四': 89, '室': 103, '室内': 104, '出血': 72, 'cerebellomedullary': 22, 'fissure': 25, 'くも膜': 42, '下': 52, 'hunt': 27, 'kosnik': 30, '分類': 74, 'grade': 26, 'ii': 28, '源': 149, '後': 113, '小脳': 106, 'pica': 36, '末梢': 138, '存在': 101, '左右': 111, 'vermian': 41, 'branch': 21, '紡錘': 183, '状': 154, '破裂': 172, '瘤': 166, '頭': 231, 'trapping': 40, '術後': 210, '神経症': 175}
コーパスのBoW表現を作成し、表示するプログラムを以下に示す。
bag_of_words = vect.transform(wakati_texts) print(bag_of_words.toarray())
実行結果は以下のとおりである。
[[2 1 0 1 0 0 1 0 1 1 1 1 1 2 2 0 2 1 1 1 1 0 0 0 1 0 0 0 0 1 0 1 3 0 0 1 0 1 1 0 0 0 0 1 1 1 1 0 0 0 1 0 0 2 3 0 1 1 1 0 2 2 0 1 3 0 1 1 2 1 1 0 0 0 0 0 2 5 1 1 1 2 1 1 2 0 1 0 0 0 0 1 0 1 0 0 3 1 1 1 1 0 1 0 0 0 0 0 0 0 1 0 1 0 0 2 1 1 0 4 0 0 0 1 1 0 0 0 1 0 1 0 0 0 1 3 1 2 0 1 1 0 0 4 1 1 0 0 1 0 0 0 0 0 0 1 5 0 0 0 2 1 0 2 2 0 0 1 0 0 1 0 0 2 1 0 0 1 1 1 1 1 0 0 0 1 1 1 0 0 1 1 1 2 0 1 1 1 0 0 1 0 2 1 1 1 2 3 1 2 0 1 0 0 0 3 1 1 0 3 2 1 1 0 1 1 3 1 0 2 0 0 0 0 0 0 2 0 1 1 0] [0 0 1 0 1 1 0 2 0 0 0 0 0 1 0 2 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 2 1 0 0 0 0 2 0 0 0 0 1 0 0 0 1 1 0 1 0 0 0 1 0 0 0 1 0 0 1 0 0 1 0 1 0 0 0 1 0 1 0 1 0 2 0 0 1 0 0 2 0 0 0 1 0 0 1 0 1 0 1 1 0 0 0 1 0 0 0 0 0 1 0 1 1 1 3 0 0 0 1 0 0 0 1 1 1 2 1 1 0 1 1 1 1 0 0 1 0 2 0 2 0 1 0 0 1 0 2 3 1 0 1 2 0 0 1 1 2 1 0 0 0 3 0 0 0 2 1 0 1 2 0 0 1 1 0 0 0 0 1 0 2 0 0 0 0 0 0 0 1 0 1 0 1 1 0 0 0 0 0 4 1 0 1 4 0 1 0 1 0 0 0 0 2 0 0 0 1 4 0 1 0 0 1 0 1 0 1 1 0 1 0 0 1 0 1 0 0 1 1 4 0 0 0 0 2] [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 1 1 1 1 1 0 1 0 0 0 0 0 2 0 0 0 1 1 1 0 0 0 0 1 0 0 1 0 2 0 1 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 3 0 1 0 0 4 0 0 0 0 0 0 0 1 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 1 0 1 1 0 1 0 0 0 3 1 0 2 0 0 0 0 0 0 0 0 1 0 0 0 1 1 0 1 0 0 1 0 0 0 0 0 1 0 1 1 0 1 0 0 0 0 0 1 0 0 0 0 2 0 1 0 1 1 0 1 0 2 0 0 2 0 0 1 0 1 1 0 0 1 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 1 0 4 0 0 0 0 0 0 0 0 0 0 0 2 0 1 0 0 0 1 2 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0 2 1 1 0 0 0 1 1 0 0]]
こうして求めたコーパスのBoW表現からコサイン類似度を計算するプログラムを以下に示す。
import math # コサイン類似度を計算する関数 def cos_sim(v1, v2): return sum(v1*v2) / math.sqrt(sum(v1**2)) / math.sqrt(sum(v2**2)) v1 = bag_of_words.toarray()[0] v2 = bag_of_words.toarray()[1] v3 = bag_of_words.toarray()[2] print(cos_sim(v1,v2)) print(cos_sim(v2,v3)) print(cos_sim(v3,v1))
実行結果は以下のとおりである。
0.2460156812380458 0.21176572077863406 0.28829998806257884
数値は異なるが、大きさの順はExcelでやったときと同じで、一番大きいのが1と3で0.288、次に1と2で0.246、最も小さいのが2と3で0.212であった。類似度がExcelの場合と違うのは、MeCabによる形態素解析で、使っている辞書が違うため、切り出される単語が異なっていることから、単語空間がぴったり一致しているわけでないからである。にもかかわらず、類似度の関係が同じになったのはこの方法があながちいい加減ではないという証だろうか。
最後に単語空間のドキュメントベクトルをCSVファイルに出力するプログラムを以下に示す。
import pandas as pd
df = pd.DataFrame(bag_of_words.toarray().T, index=vect.get_feature_names(), columns=['v1','v2','v3'])
display(df)
df.to_csv('/content/drive/MyDrive/Colab Notebooks/vector.csv')
このプログラムを実行する前にGoogleドライブをマウントしておくことを忘れないように。作成したCSVファイルは[マイドライブ]>[Colab Notebooks]の下に「vector.csv」と言うファイル名で作成される。
 |
| 実行結果 |
機械学習
コーパス
医学中央雑誌にキーワードとしてそれぞれ「ネフローゼ症候群」および「一過性脳虚血発作」と入力して得られた症例報告の検索結果のAbstractを各々200件集めてコーパスとした。
 |
| 医中誌で検索したAbstract |
1列目がキーワード、2列目がAbstractである。
これをGoogleドライブの[マイドライブ]>[Colab Notebooks]へ「abstract.txt」というファイル名でアップロードし、以下のプログラムで読み込んでデータフレーム abstract_df を作成した。
import pandas as pd abstract_df = pd.read_csv(filepath_or_buffer="/content/drive/MyDrive/Colab Notebooks/abstract.txt", encoding="utf_8", sep="\t")
こうして作成したデータフレームabstract_dfを以下に示す。
 |
| CSVから読み込んだデータフレームabstract_df |
データセットの作成
データフレームabstract_dfから機械学習に用いるデータセットを作成する。まず、列'abstract'を抽出し、文字列リストに変換し、MeCabで形態素解析して名詞だけを抜き取って分かち書きし、それをCountVectorizerによってBoW表現するプログラムを以下に示す。
texts = list(abstract_df['abstract']) wakati_texts = [wakati_gaki(text) for text in texts] vect = CountVectorizer(token_pattern='(?u)\\b\\w+\\b') vect.fit(wakati_texts) bag_of_words = vect.transform(wakati_texts) data = bag_of_words.toarray() feature_names = vect.get_feature_names()
dataにBoW表現したAbstractデータが格納され、特徴量名称はfeature_namesに文字列リストとして格納される。
次に教師データであるdisease列について、「ネフローゼ症候群」を0、「一過性脳虚血発作」を1にしたtargetリストを作成する。
import collections disease = list(abstract_df['disease']) target_names = list(collections.Counter(disease).keys()) target = [target_names.index(d) for d in disease]
まず、データフレームのdisease列を取り出して文字列リストdiseaseにし、それをcollectionsのCounterメソッドを使って集計し、そのkey配列を取り出してラベル名称リスト(target_names)を作成する。最後に、そのラベル名称リストを用いて文字列リストdiseaseから教師データtargetを作成する。これは、病名を対応するインデックスに変換したインデックスリストになっている。
教師あり学習
機械学習に用いるデータセットが整ったので機械学習モデルの作成と評価を行う。機械学習モデルとしてここではロジスティック回帰モデルを作成する。
まず、必要なライブラリを読み込む。
!pip install mglearn !pip install japanize-matplotlib import mglearn import numpy as np % matplotlib inline import matplotlib.pyplot as plt import japanize_matplotlib import pandas as pd from IPython.display import display import scipy as sp
訓練用及び検証用データセットの作成
まず最初に訓練用及び検証用データセットの作成を行う。これは、作成したデータセットを分類モデルを訓練するために用いるデータセットと作成したモデルを評価する検証用データセットに分ける作業である。
from sklearn.model_selection import train_test_split
index = np.array(list(range(len(data))))
X_train, X_test, y_train, y_test, i_train, i_test = train_test_split(
data,
target,
index,
random_state=0
)
train_test_split関数によってデータセットの3/4が訓練用、1/4が検証用にランダムに分けられ、それぞれX_train, X_testに格納される。対応する教師データはそれぞれy_train, y_testに格納される。
ところで、train_test_split関数は元のデータをシャッフルして訓練用と検証用に分割するので、分割後のX_trainやX_test(そしてy_trainやy_testも)が元のコーパスの何番目のデータであったかわからなくなる。そうなると誤分類分析など分類結果の評価をする際に困難が生じる。そこで、元のコーパスのインデックスを保持したリストindexを作成して、それをtrain_test_split関数の3番目のリスト引数に指定し、訓練用と検証用に分割することによって元のコーパスと紐づける。 例えば検証用データの元のコーパス上の添え字はi_testに格納されているので、この情報を用いて次のようにして元のコーパスデータにアクセスできる。
np.array(texts)[i_test]
ここで、Abstractリストであるtextsをnp.array関数でNumpy配列にしているのは、Pythonリストは引数にインデックスリストを指定できないので、それができるNumpy配列に変換しているからである。textsをdiseaseやdata, targetに変えれば、各々の検証データのリストが得られる。
分類タスクの実行と評価
分類タスクの実行と評価を行うプログラムを以下に示す。
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression().fit(X_train, y_train)
print(f'Training set score:{logreg.score(X_train, y_train):.3f}')
print(f'Test set score:{logreg.score(X_test, y_test):.3f}')
実行結果は以下の通り。
Training set score:1.000 Test set score:0.930
この結果を見ると、訓練用データに過適合している模様。
混同行列
混同行列を作成するプログラムを以下に示す。
from sklearn.metrics import confusion_matrix
pred_logreg = logreg.predict(X_test)
scores_image = mglearn.tools.heatmap(
confusion_matrix(y_test, pred_logreg),
xlabel='予測されたラベル',
ylabel='真のラベル',
xticklabels=target_names,
yticklabels=target_names,
cmap=plt.cm.gray_r,
fmt="%d"
)
plt.title("混同行列")
plt.gca().invert_yaxis()
作成された近藤行列を以下に示す。
 |
| 混同行列 |
誤分類
分類器が誤分類したケースを抽出してCSVファイルに出力するプログラムを以下に示す。
# 誤分類フラグ
f = pred_logreg != y_test
# 誤分類インデックス
i = i_test[f]
# 誤分類ケースをデータフレーム化
df_error =pd.DataFrame(
{
"index": i,
"disease": np.array(disease)[i],
"abstract": np.array(texts)[i]
}
)
df_error.to_csv("/content/drive/MyDrive/Colab Notebooks/誤分類.csv", sep=",")
df_error
実行結果を以下に示す。
 |
| 誤分類 |
index列は元のコーパスの誤分類されたデータポイントのインデックスを示す。disease列は正解ラベルで、例えばindex=348のAbstractは正解ラベルが「一過性脳虚血発作」であるにもかかわらず、構築した分類器が「ネフローゼ症候群」と分類した事例を示している。
以下にそのAbstractを示す。
24歳男。3歳時に低身長と蛋白尿を指摘され、その後ステロイド抵抗性ネフローゼ症候群となり、腎生検で巣状糸球体硬化症(FSGS)と診断された。その後更に慢性腎不全に進行してCAPD導入され、6歳時に腎移植目的で入院した。独特な顔貌などのため複合糖質代謝異常症を疑ったが、尿中にムコ多糖やオリゴ糖の排泄はなく、培養皮膚線維芽細胞でのリソーム酵素活性も正常であった。なお、骨X線では脊椎骨端異形成症の所見を認めた。腎移植後の経過は良好で、移植後10年の腎生検でもFSGSの再発はみられなかった。12歳時よりステロイドは中止し、シクロスポリン、ブレディニンを継続したが、成長障害の改善はなかった(最終身長110cm)。内分泌学的検査で異常はなく、臨床経過に加え、移植術後に一過性の白血球数減少があり、10歳頃より皮膚の色素沈着が目立ってきたことより、14歳時にSchimke immuno-osseous dysplasiaと診断した。その後も重篤な感染症や一過性脳虚血発作、神経学的異常はなく、頭部CT、心エコーも正常であった。
ここで、青字は一過性脳虚血発作を特徴づける単語で赤字はネフローゼ症候群を特徴づける単語である。このAbstractには正解ラベルである一過性脳虚血発作という単語がそのまま含まれているにもかかわらず分類器はネフローゼ症候群と分類したのは、ネフローゼ症候群の特徴語である「腎」という単語が5回も出現していたからである。「腎」のロジスティック回帰係数は-0.491であるが、それが5回出現したことで-2.455という値になった。さらに「ネフローゼ」が-0.942、「症候群」が-0.744と、ネフローゼ症候群を特徴づける語が頻出している。一方、「一過性脳虚血発作」という単語のロジスティック回帰係数は0.706に過ぎない。
ロジスティック回帰係数
作成されたロジスティック回帰モデルの回帰係数はlogreg.coef_に格納されている。これをCSV形式のファイルに出力するプログラムを以下に示す。
df = pd.DataFrame(
data=logreg.coef_.T,
columns=['回帰係数'],
index=feature_names
)
df.to_csv("/content/drive/MyDrive/Colab Notebooks/logreg.coef_.csv", sep=",")
回帰係数を昇順に並べ替えたものを以下に示す。
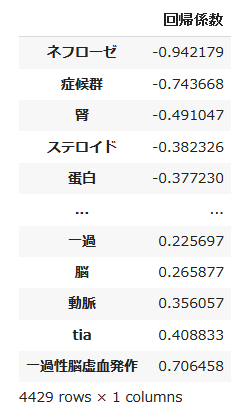 |
| 回帰係数 |
これを見ると、「ネフローゼ」「症候群」や「一過性脳虚血発作」「TIA」など、正解ラベルの単語がAbstractへ入っていて、それらが分類に大きく貢献しているように思える。当然といえば当然のことであるが、これでは面白みがない。そこで、関数wakati_gakiを修正して、除外用語をオプションに指定(下記プログラム中の第2引数に指定したexclusion_words)できるようにして、これらの単語を除外して分かち書きを行い、それに基づいてBoW表現を得て分類を行った。
def wakati_gaki(text, exclusion_words = []):
tagger = MeCab.Tagger()
node = tagger.parseToNode(text)
words = []
while node:
POS = node.feature.split(',')[0]
if POS in ['名詞']:
if not node.surface in exclusion_words:
words.append(node.surface)
node = node.next
return ' '.join(words)
これに伴って分かち書きにするプログラムは次のようになる。
wakati_texts = [wakati_gaki(text,['TIA','ネフローゼ', '症候群', '一過性脳虚血発作']) for text in texts]
その結果、次のような結果を得た。
Training set score:1.000 Test set score:0.900
訓練用データに対するAccuracyは1.0であるが、検証用データでは0.9になって、正解率が少し下がった。それでも9割の正解率があるのはすごい。この場合の混同行列とロジスティック回帰係数を以下に示す。

|
| ラベルを除去した場合の混同行列 |
 |
| ロジスティック回帰係数(ラベル除去) |
混同行列を見ると、一過性脳虚血発作の誤分類が4から7に3つ増えている。また、ロジスティック回帰係数からはラベルを表す単語が除去されている。これを見ると、「胃」「ステロイド」「蛋白」「浮腫」「尿」はネフローゼ症候群の、「動脈」「一過」「脳」「出現」「塞栓」は一過性脳虚血発作のAbstractを示す特徴であることがわかる。
それにしても、わずか300個のAbstractで訓練したにもかかわらず、9割を超えるAccuracyを持つ分類器ができあがったのは驚きである。
Doc2Vec
論文の抄録を集めてコーパスを作成し、Doc2Vecで類似文書検索を行ったのでまとめておく。抄録コーパス wakati_texts の作成については「データセットの作成」を参照のこと。
from gensim.models.doc2vec import Doc2Vec, TaggedDocument documents = [TaggedDocument(doc, [i]) for i, doc in enumerate(wakati_texts)] model = Doc2Vec(dm=0, vector_size=50, min_count=1, alpha = 0.025) model.build_vocab(documents) model.train(documents, total_examples=model.corpus_count, epochs=100) # k番目の文書と類似の文書 k = 10 print(documents[k]) for i, x in model.docvecs.most_similar(k, topn=3): print(i, x, documents[i])
実行結果は次のようになる。
TaggedDocument(リツキシマブ ( RTX ) 晩期 合併症 発 性 中 球 減少 症 ( late - onset neutropenia : LON ) , ネフローゼ 症候群 骨髄 所見 報告 . , RTX 投与 後 LON ( R - LON ) 発症 機 序 未知 . 難治 性 ネフローゼ 症候群 RTX 投与 3 か月 後 LON 症例 骨髄 検査 施行 . 骨髄 所見 末梢 血 CD 20 細胞 推移 R - LON 発症 機 序 考察 . 症例 7 歳 女児 . 難治 性 ネフローゼ , RTX ( 1 回 375 mg / m 2 ) 4 回 投与 . 最終 投与 2 か月 半 後 発熱 Grade IV 顆粒 球 症 . 骨髄 検査 骨髄 球 系 分化 停止 所見 . とき 末梢 血 CD 20 細胞 0 . 05 % , 1 か月 後 1 . 5 % , 2 か月 後 7 % 正常 化 . 以上 B 細胞 回復 直前 LON 発症 . RTX 投与 後 B 細胞 回復 前 白血球 数 , 白血球 分 画 注意 必要 .( 著者 抄録 ), [10]) 252 0.5759676694869995 TaggedDocument(最近 筆者 ら , めまい 自分 部屋 徘徊 症例 経験 発症 後 3 日 目 MRI , 右 海馬 , 拡散 強調 像 ( diffusion - weighted image ; DWI ) 信号 , ADC ( apparentdiffusion coefficient ) map 信号 発症 後 10 日 目 , 発症 後 17 日 目 MRI , FLAIR ( fluid . attenuated inversion recovery ) 像 , T 2 強調 像 脳 梗塞 所見 海馬 一過 性 虚 血 病巣 めまい 報告 例 , 投稿 ( 著者 抄録 ), [252]) 378 0.5115715861320496 TaggedDocument(高齢 化 弁膜 症 性 心房 細 動 ( nonvalvular atrial fibrillation : NVAF ) 患者 心 原 性 脳 塞栓 はじめ 血栓 塞栓 症 合併 比率 増加 ため 臨床 現場 凝固 製剤 ワルファリン こと 日常 的 ワルファリン 治療 域 維持 コントロール 困難 休 薬 減 薬 必要 際 管理 複雑 ため 正確 回 プロトロンビン 時間 ( prothrombin time - international normalized ratio : PT - INR ) 凝固 能 モニタリング こと 不可欠 ワルファリン 療法 中 PT - INR 低下 ワルファリン 用量 不足 脳 梗塞 ( cerebral infarction : CI ) 一過性脳虚血発作 ( transient ischemic attack : TIA ) stroke ( 卒 中 ) 難治 性 NVAF 患者 13 年間 長期間 臨床 経過 報告 NVAF 発症 stroke 成り行き 観察 この間 様々 イベント 反省 臨床 医 注意 喚起 ( 著者 抄録 ), [378]) 258 0.4994485378265381 TaggedDocument(症例 特記 既往 41 歳 男性 2013 年 毎回 3 ~ 5 分間 持続 急 右 上下 肢 脱力 訴 一過性脳虚血発作 診断 5 日間 入院 アスピリン 投与 退院 4 日 後 再発 ため 入院 NIHSS 評価 スコア 7 中等 度 白血球 数 減少 ヘモグロビン 軽度 減少 明らか 血小板 減少 播種 性 血管 内 凝固 症候群 アラニンアミノトランスフェラーゼ グルタミン酸 オキサロ 酢酸 トランスアミナーゼ 数値 上昇 骨髄 スメア 末梢 血 スメア 所見 骨髄 球 核 型 それぞれ 89 %、 51 % こと t ( 15 ; 17 )( q 22 ; q 12 ) 急性 骨髄 球 性 白血病 診断 臨床 所見 進行 性 神経 症候 増悪 意識 混濁 尿 失禁 入院 24 時間 以内 NIHSS スコア 10 増悪 頭部 MRI 検査 播種 性 信号 領域 観察 ため オールトランスレチノイン 酸 導入 化学 療法 開始 入院 6 日 目 死亡, [258])


0 件のコメント:
コメントを投稿